
It is almost a commonplace now that we – and our stuff – is making an awful lot of data. According to IBM, 90% of all data that there has ever been was produced in the last two years.
As Cisco points out, a huge proportion of that data – perhaps as much as 80% – will be video. But much of that video is not something that anyone will ever want to watch. It may be CCTV or other monitoring footage, or road webcams. This video that is being captured to provide information capable of being analysed, not entertainment. Nevertheless, huge amounts of this kind video is being transported, processed and stored. This is expensive and does not scale. Moreover, it inevitably creates problems for privacy and thus for regulation.
Lots of companies are attempting to solve this problem. Many of them focus on ways to process the data after it’s been captured so as to save on storage. There is a good summary of some of the different approaches being taken in this article, and in the comments below.
Recently we have met with two companies that have taken a rather different approach to using image-based data in Internet of Things (IoT) applications.
The first of these is Apical, which licenses technology used in cameras and displays and smartphones. It sells designs to chipmakers who embed its ideas into silicon. Its technology is now in a billion devices, and has some of the essential IPR in High-dynamic-range imaging (HDR). Apical has been in existence for 12 years and has 85 employees from 22 nationalities.
The essence of its cleverness already comes from the principle of dealing with digital images in a way that is based on an understanding of how the eye processes them. In terms of processing video data, what Apical does is look at the way the visual system handles images of human movement, again so as to enable processing at the edge. We know a lot about how people move their body parts about, and often it’s those aspects of an image that contain the information that we need. Using heuristics about how images change as a result of these kinds of movement can be used to pre-process the image into information before, rather than after, it is presented to a human for interpretation. As information it can be handled by other kinds of data processing system, in a way that video can’t. Apical calls its new emerging technology ‘Spirit’. It is not yet commercial. Apical has it working, on FPGA chips, typically used for prototyping. The next task is to put into ASICs; it could be in the market by the end of 2015, says Apical CEO Michael Tusch.
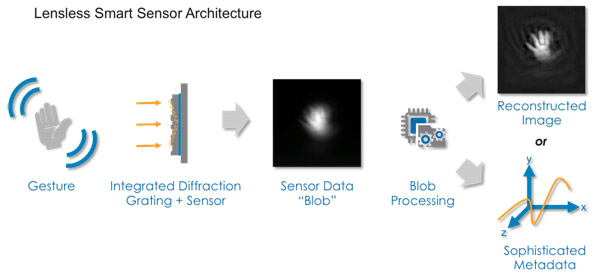
The other interesting company is Rambus, based in Silicon Valley, which we met at Mobile World Congress 2015. This a US-based technology licensing company has developed lens-less smart sensors, which are not cameras and which capture a much smaller data set from the environment. These use diffraction gratings rather than lenses to partially focus the inbound light on to a sensor, and use processing power and smart algorithms to turn this light into information. This might include turning it into something much more like a conventional picture, but it need not – particularly if the point of gathering the data was to produce the information rather than pictures.
The Rambus approach represents a conscious departure from the way that the human eye works; in some ways it is doing the opposite of what Apical does. The conventional approach to image capture is essentially to use a lens to focus a light array on to something sensitive.
Rambus’s alternative is to throw processing power at the light array rather than to rely on a lens to improve the acuity of the image that is captured. Moore’s law says that processing power gets cheaper, and takes up less space, each year. Lens-less sensors are cheaper than their camera equivalents; a conventional lens-based camera-like sensor can cost anywhere from USD1 to USD10. The company claims that with a sufficiently large order lens-less sensors could be made for much less than USD1. They can also be much smaller, by a factor of around 50; and they also require less power, according to Rambus. Some of these advantages derive from the fact that they can be specifically designed for a single purpose, rather than the more ‘horizontal’ approach that is implicit in a lens-based camera. The grating, and the sensor and processor can all be optimized for the use case.
This kind of sensor thus places less demand on both transmission and storage. This makes them potential candidates for a wide range of IoT applications; Rambus describes itself as offering the ‘eyes of the IoT’, which at least makes for a catchy strapline.
Right now we are not making any bets on which of these two approaches will prove most suitable for dealing with the video data tsunami, or whether both will find domains in which they can dominate. But we expect to hear a lot more about both of them, and about other approaches to addressing this problem.









