
On November 9, 2016, the day after the US presidential election, people all over the world woke up to the same surprise they had when they woke up on June 24, the day after the Brexit referendum: the polling data they thought they could believe was, in fact, irrelevant. That data, so assiduously collected and analysed, resulted in assumptions that were the opposite of eventual outcomes.
The American Association for Public Opinion Research immediately announced after the election that it was setting up a committee to investigate the accuracy of polls, methodologies used and differences with past elections. There will be analysis as to why the correct information wasn’t provided, but a likely factor is the perceived lack of anonymity. Another factor may be that the electorate, in the age of social media and privacy concerns, wants to know what’s in it for them. Essentially, there is now an established social and economic contract whereby people will hand over their information in exchange for a perceived benefit, such as using a website or app they like. All well and good, but how does this affect the concept of privacy and IoT? In our recent report, IoT and privacy: compliance, trade-offs and opportunities, it was noted that one of the key users of data was smart cities. If collecting data from citizens is incomplete or inaccurate, then smart cities applications will be sub-optimal and the smart city paradigm moot.
Tapping into public opinion and information in a way that does not engender true responses, or valid data, means that the correct city services won’t be provided. Moreover, politicians and some civic administrators place great emphasis on key stakeholder – citizens – buy-in as ratepayers and voters. Consequently, if data collected isn’t accurate, smart cities administrators enter into a vicious circle: lack of services buy-in results in services people don’t need which results in services people don’t use, and back again.
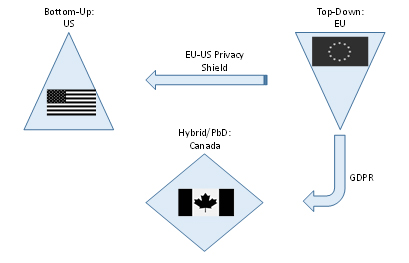
On a national level, governments have been trying to help with these concerns and manage issues of privacy in the era of big data through legislation and compliance. There is no consensus as to how to address privacy from a policy perspective, as evidenced by legislation differing globally. As a result, jurisdictions create privacy policies based on their differing economic and political philosophies. Specifically, the US takes a much more US constitution-based, “individual/corporate freedoms” approach whereas the EU takes a “good for the society” approach; the former being “bottom-up” and the latter being “top-down” in its way of applying privacy rules. The US also uses a sectoral approach, regulating specific risks in certain contexts in verticals such as healthcare and financial services, due to its citizen’s particular sensitivity over their data in both these areas. In regulating specifically rather than broadly, the US believes it better helps businesses to innovate. In contrast, the EU views privacy as a fundamental human right, which translates into broad rules restricting the use of data and the data that is used, requiring explicit consent. Canada stands in the middle, offering a hybrid approach between the two, Privacy by Design (PbD), as can be seen in the visual below.
(Source: Machina Research 2016)
In the era of IoT, the focus is on enabling machines to provide us with data which in turn provides analytics to offer real-time decision-making and predictions. An equally key source of data is one which involves humans, be it through access to metadata, customer lists, and social media. Without the integrity of the latter, there is a risk for low quality IoT solutions.
A former tech industry colleague was randomly selected for a recent government online survey to help all levels of government make planning and investment decisions. He viewed the level of privacy intrusion as uncomfortable and highly sensitive: for example, it asked for the names and ages of his children, as well as what school they attended and its address. To him, the minutiae of detail didn’t seem to be in keeping with the more basic level of data required to determine city traffic patterns. Arguably, goals could have been more easily accomplished by asking if any children in the house used transportation to get to school, which type, and distance. Additionally, looking at the privacy statement revealed that not only had the government engaged a private research firm to administer the survey, but further burrowing into said firm’s own privacy statement revealed that they could engage their own third party to perform functions on their behalf, albeit having to comply with their privacy policy and statutory obligations.
In summary, this colleague had to spend half an hour of his time, provide sensitive information with an amount of detail not warranted by the objective, to then have it processed by third party research firm who would possibly hand it over to an undisclosed other third party. If we look at data privacy in the context of an economic trade, in this case there was no perception of value in return for both his time and the extensive amount of sensitive personal data shared, so he didn’t provide his data. Furthermore, he perceived that there was little transparency in terms of who would be collecting, using, disclosing and retaining his data which created a lack of confidence, contributing to the negative outcome.
What a tech industry colleague’s episode, the US election and the UK referendum all show in terms of privacy and the IoT should be concerning to smart cities and other jurisdictions: if you cannot guarantee anonymity and you cannot provide a good reason why citizens should give you their data, they won’t; or if they do, that data won’t necessarily be valid. The resulting city applications won’t necessarily be so smart.

By Isabel Chapman, principal research analyst,
Machina Research









