The Internet of Things is conjuring up new challenges. Many IoT services are still in their infancy, and we’re only just hitting the teething problems – one of the most significant of which will be architecting suitable data platforms.
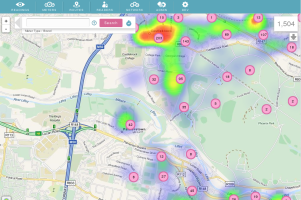
Over the past few years, like many companies under the IoT umbrella, Temetra has undergone an intense period of growth. The volume of data we collect has increased by a factor of five. Temetra now ingests, stores and analyses pressure and flow data from over 12 million water meters, which our customers use to do everything from automatic meter reading to identifying potential leaks, says Paul Barry, director at Temetra.
The reliability of readings and the availability of their data is absolutely critical to our customers, who must be able to access meter data across all their sites at all times. However, delivering optimum service reliability was becoming increasingly difficult as our customer base, and our customer’s businesses grew. For some data types, our underlying PostgreSQL database was starting to show the strain, so we knew we needed to find a solution or risk sacrificing our growth.
The IoT has phenomenal potential to transform many aspects of all our lives – a decade from now almost everything could be connected – but we have found as a business that there are lessons the service providers need to learn. If you can’t scale an application with the infrastructure, the huge datasets introduce new problems associated with managing larger backups, and delayed master-slave replication.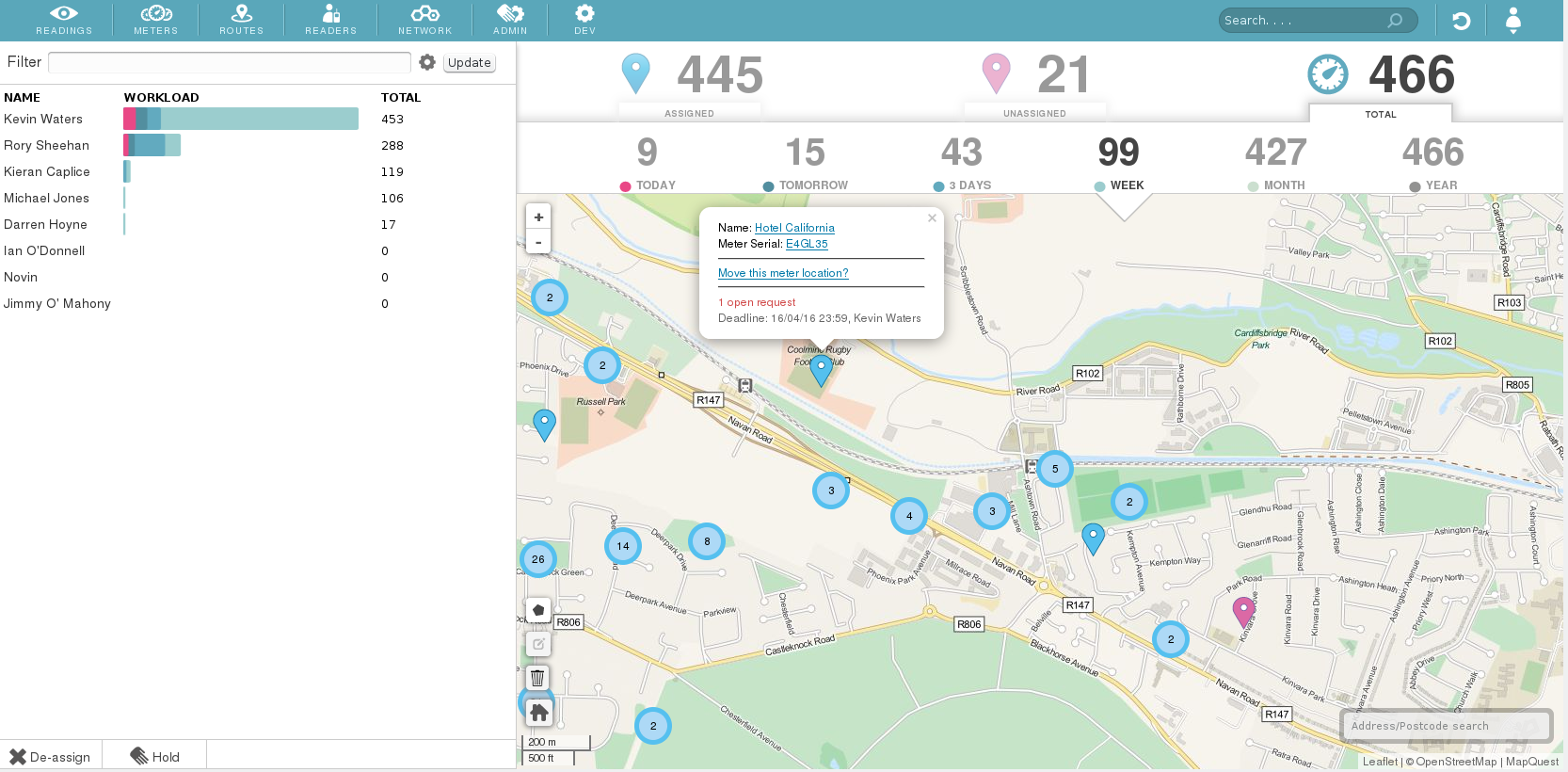
In our case, we knew the situation was likely to get more difficult the faster we grew our service, so we began investigating new ways to distribute our data. In 2010, we began looking at the emerging wave of NoSQL technologies, as the scalability they promised seemed geared towards the specific business challenges of the IoT.
NoSQL favours availability, scalability and resiliency having been designed to solve the data challenges of Facebook or Google, which required a database that could write and read data anywhere, while scaling and delivering across large data sets and millions of users.
We knew we needed to handle more and more so-called time series data such as meter readings or alarms produced by transponders that can arrive at high speeds, and so required a database that could support very rapid reads and writes.
During the assessment process our IT team looked at all the main NoSQL players including Riak, MongoDB, Cassandra and Redis. We got to grips with Riak the quickest, and had an evaluation up and running within an hour.
The other serious contender was Cassandra, but in our experience it proved to be time consuming to administer, so we ultimately opted for Riak. The next step was to move our core data from Postgres to NoSQL, although I should note we still run Postgres for certain types of data as it has some very desirable features when dealing with data integrity and transactions.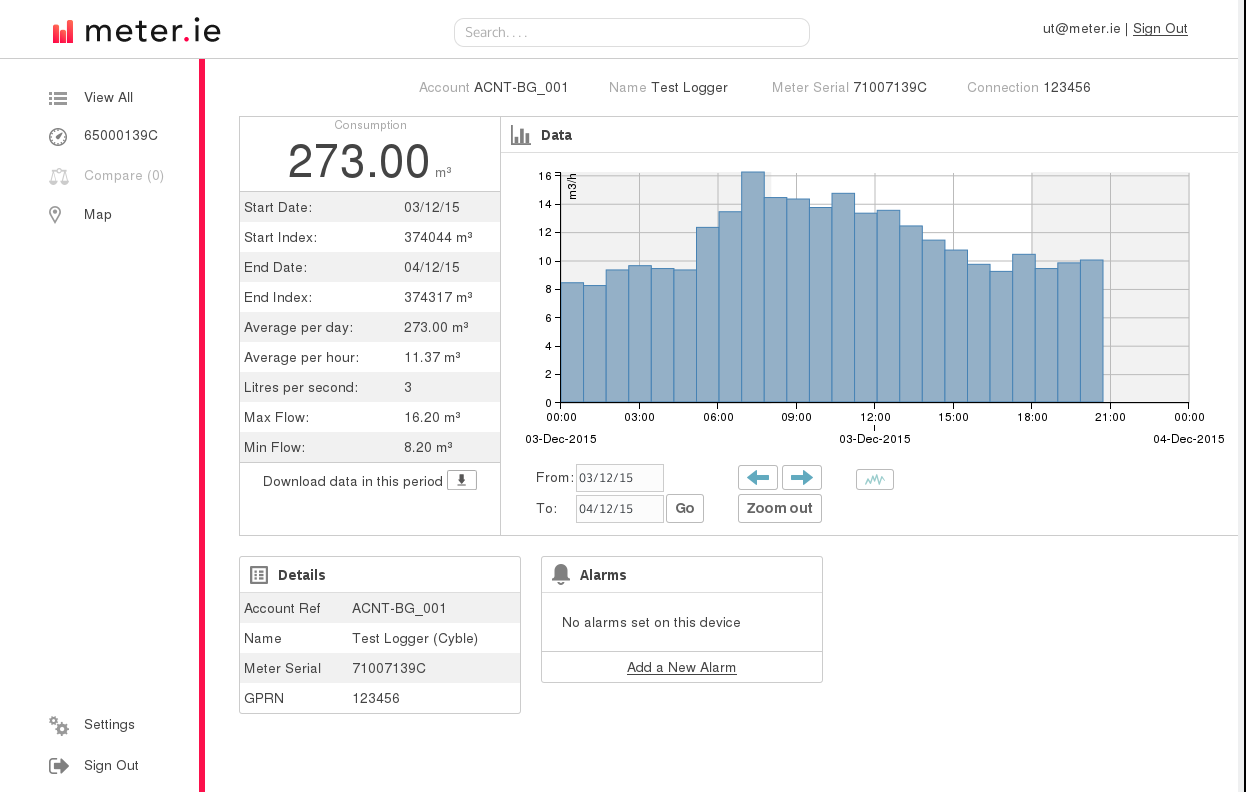
We then went through an extended period of testing which lasted approximately two years, during which time we found that NoSQL was able to scale whenever we added readings and had the potential to become a very resilient foundation to our application.
Like many others in our position we kicked off by using the open source version, but as we got more comfortable with the software, and more of our customers began to rely on it, we moved to the enterprise grade version with per-node support from Basho to provide expertise in the event of any problems.
Like a lot of companies, we’re now interested in pulling in more and more sensor data. In our case it will likely be specific data types that have value to utilities that we can aggregate and analyse alongside the meter data. Now that we have a distributed application platform that can manage a high volume of time-series data reliably without much administration, we’re also interested in seeing how we can add value in the future and take advantage of the development hours that are freed up to work on new features.
Ultimately, our customers are after a boringly reliable service. In addition to our NoSQL platform, we’re looking closely at open source projects such as Apache Spark and Apache Storm, which will allow us to carry out more distributed compute time analysis.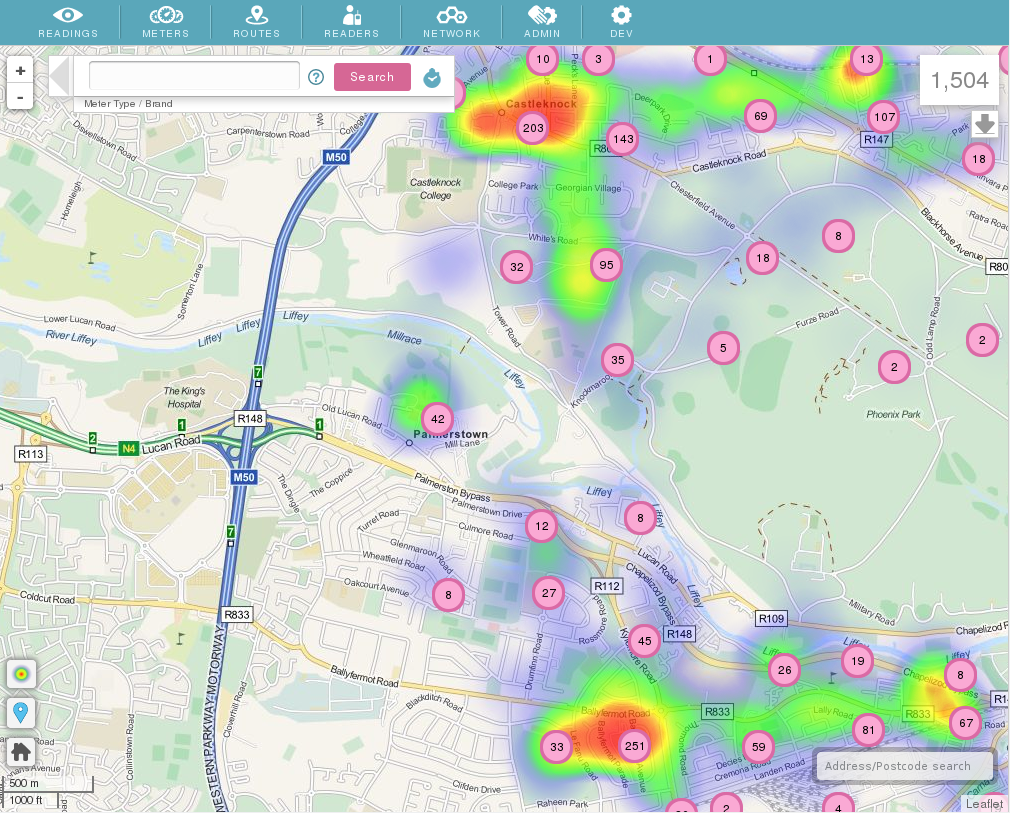
Our aim is to continue using these emerging technologies to get the scalability right so we can add millions of meters. Our growth is predictable, so the key is making sure our search and data analysis still works when we get to the next milestone.
Temetra operates a software-as-a-service, delivering edge data management tools to individual, discrete metering networks without the need for costly infrastructure at every site. We built our business back in 2002 around the Internet’s potential to collect and analyse data.
Our web-based Meter Data Management service is designed for water, gas and heat meter utilities, storing a mixture of eye-ball, low-power radio Automatic Meter Reading (AMR), and fixed network high-frequency meter index data, along with meter asset and network management data. Beyond billing, this mass of data allows us to do a number of things, including identifying potential leaks and alerting the relevant parties.
The author of this blog is Paul Barry, director at Temetra.
Comment on this article below or via Twitter: @IoTNow_ OR @jcIoTnow









