
Hyperconverged secondary storage looks set to play a pivotal role in enterprise IoT environments. It allows enterprises to better manage the increasing amount of data created by devices.
In addition, says Bob Emmerson, it facilitates the seamless exchange of data between the Information Technology (IT) domains and Operational Technology (OT) domains, which is a mandatory requirement for IoT systems.
Regular secondary storage employs silo solutions, e.g. one for backups, another for analytics, another for files and so on, which is inefficient. Cohesity’s software-defined platform consolidates all the secondary data onto a single data platform that runs on hyperconverged nodes (industry-standard x86 servers). This means that all the secondary storage silos are consolidated within the data centre.
As illustrated in figure 1, similar software-defined platforms at the network edge run in VMs on shared physical servers. Having the platform in both locations enables remote sites to replicate all local data in the central data centre for secure backup and recovery.
This enables the creation of a data fabric that goes from virtual machines consolidated at the edge through to the secondary storage data centre and on to the cloud. This means that the data platform enables the creation of a data fabric that goes from data that is generated and consolidated at the edge, through to the secondary storage data centre and on to the cloud.
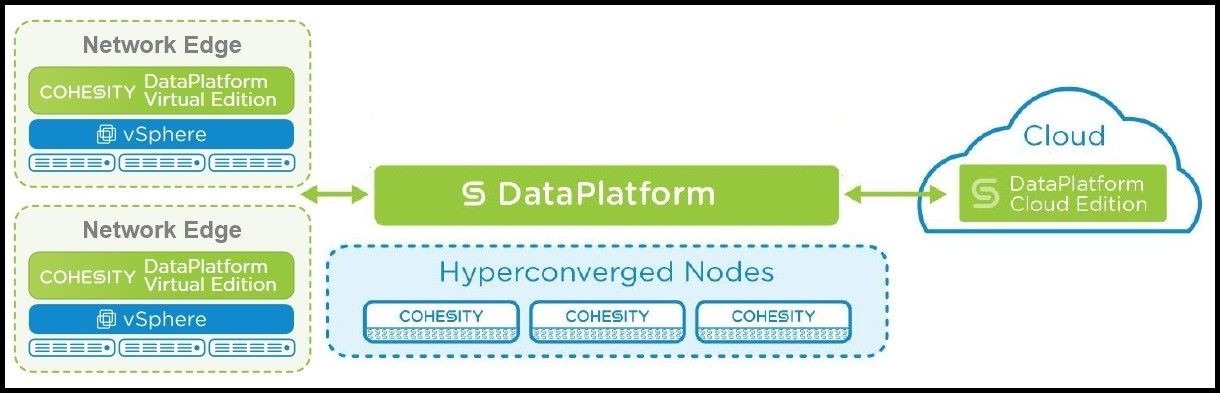
The IoT action takes place at the network edge. The edge can include remote branch offices such as retail outlets and distributed data points for wind farms or fleets of trucks. When data platforms are deployed at these locations the results of processing and analysing data in distributed networks can be aggregated and replicated in the central data platform.
This architecture also enhances the functionality of the cloud. It can continue to be employed as a low-cost way of archiving long-term data, but interoperability allows data to be replicated across locations and to be managed using the same user interface as the on-site data centre.
Part 3 of this blog follows tomorrow.
The author of this blog is Bob Emmerson, freelance IoT writer and commentator
Comment on this article below or via Twitter: @IoTNow_OR @jcIoTnow









